
2 R toolkit para la ciencia de datos
Objetivos
Instalar el software R y su IDE (Entorno de Desarrollo Integrado) RStudio.
Informes reproducibles con
quartoy control de versiones conGitHub.Conocer los fundamentos del modelo CRISP-DM.
2.1 R y RStudio
2.1.1 Instalación de R y RStudio
R es un entorno de software libre para la computación estadística y los gráficos. Se compila y ejecuta en una amplia variedad de plataformas UNIX, Windows y MacOS. Las fuentes, los binarios y la documentación de R pueden obtenerse a través de CRAN1. Para descargar R elija su espejo CRAN preferido en www.r-project.org.
RStudio es un entorno de desarrollo integrado (IDE) para R. Incluye una consola, un editor que resalta la sintaxis y admite la ejecución directa del código, así como herramientas para el trazado, el historial, la depuración y la gestión del espacio de trabajo. RStudio está disponible en ediciones comerciales y de código abierto y se ejecuta en el escritorio (Windows, Mac y Linux) o en un navegador conectado a RStudio Server o RStudio Workbench (Debian/Ubuntu, Red Hat/CentOS y SUSE Linux), está disponible en www.rstudio.com.
Note
El orden es importante:
Instale R.
Instale RStudio.
Compruebe que tiene instalados los iconos de la Figure 2.1 y abra RStudio.
2.1.2 Interfaz de RStudio
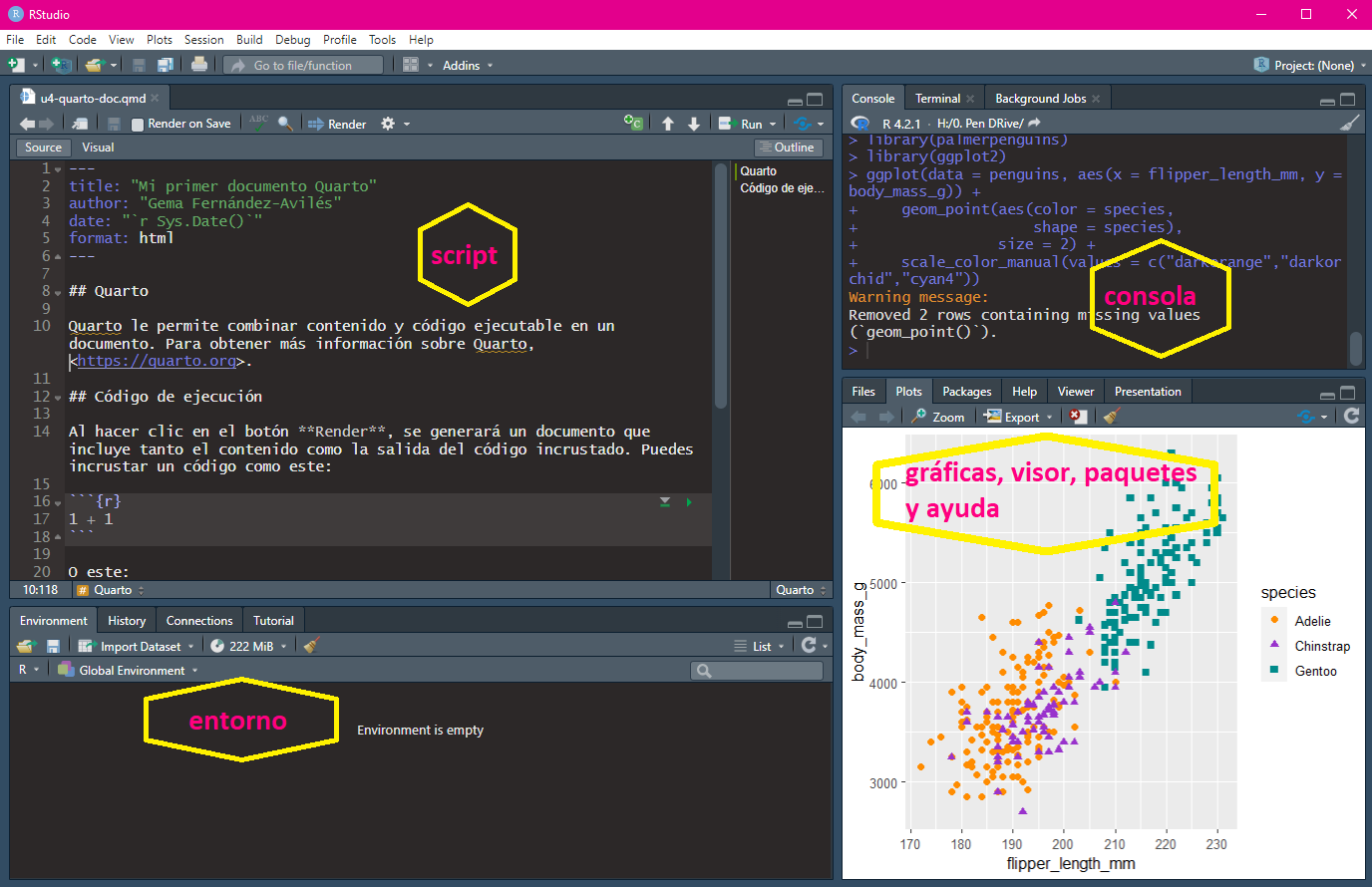
Al abrir el programa se observan cuatro paneles (véase Figure 2.2).
Sripts: para escribir código.
Consola: contiene la Consola, Terminal y los Jobs.
Entorno: contiene el Environment, History, conexiones y Git, entre otros.
Files, Plots, Packages, Help y Viewer
La posición de los paneles se puede personalizar al gusto del usuario, al igual que la apariencia del IDE.
Note
La posición relativa y el contenido de cada panel pueden personalizarse desde el menú: Tools > Global Options > Pane Layout
2.1.3 Instalación los paquetes
Los paquetes son adiciones modulares al software R que añaden funcionalidad en forma de nuevas funciones, conjuntos de datos, documentación, etc. El repositorio estándar de paquetes R es “Comprehensive R Archive Network” (CRAN).
Note
Ofrecen un breve resumen de los paquetes incluidos.
Los paquetes se instalan con la función base de R install.packages():
install.packages("tidyverse")
Note
Los paquetes se instalan una única vez y se leen cada vez que se utilizan.
Alternativamente, se pueden instalar desde el panel de Paquetes en RStudio desde una interfaz gráfica.
2.1.4 Proyectos
Ser organizado desde el principio es uno de los mejores hábitos y en R esto se consigue trabajando con proyectos. Un proyecto de R agrupa todo los ficheros del trabajo en una carpeta de forma que se facilita su manejo, el trabajo colaborativo y su reproducibilidad.
Note
Crear un proyecto Quarto en R:
Desde el menú: File > New Project y luego elija:
Nuevo DirectorioProyecto VacíoElija un nombre para el directorio, por ejemplo,
mi_proyectoHaga clic en
Crear Proyecto.
📁 data: para los datos.
📂 img: para las imágenes.
📂 src: contiene los scripts de R para llevar a cabo las distintas tareas del análisis.
📁 output: se guardarán los resultados finales de nuestro análisis.
README.md debe contener la información básica sobre el proyecto, la compatibilidad, los inputs que necesita, los outputs que genera y un resumen de flujo del trabajo. Ésto ayudará a cualquiera a comprender mejor cómo es nuestro proyecto.
Una de las estructuras más comunes es la mostrada en la Figure 2.3:

Note
Los distintos scripts se pueden ejecutar desde otros scripts. Para ello se utiliza la función source()
2.1.5 Trabajar con un script de R
Para comenzar a escribir un script nuevo nos dirigimos a File > New File. Los más utilizados actualmente son:
📓 > R Script.
📖 > Quarto document.
📓 > R Notebook.
📄 > R Markdown.
Note
Si se tiene creado un proyecto Quarto mejor trabajar con un un quarto document para luego renderizar todo el documento. Véase Wickham and Grolemund (2016) para un estudio profundo de proyectos.
El editor es un editor de texto plano (sin negritas ni cursivas) pero ofrece un código de colores del texto dependiendo de lo que se escriba (resaltado de sintaxis).
Es extremadamente útil comentar el script con información adicional para hacer más claro el proceso de programación. Para añadir un comentario, simplemente hay que poner # al comienzo de la linea y lo que esté a la derecha no será ejecutado.
Finalmente, a la hora de escribir código en R lo más conveniente es usar las buenas prácticas diseñadas por programadores expertos. Para ello, lo mejor es aplicar una guía de estilo 📖, cuyo objetivo es hacer que nuestro código R sea más fácil de leer, compartir y verificar. Una de las mejores guías es The tidyverse style guide.
2.2 El ecosistema tidyverse
![]()
El tidyverse es una colección de paquetes de R para la ciencia de los datos. Todos los paquetes comparten una filosofía de diseño, una gramática y unas estructuras de datos subyacentes. Se basan en la idea tidy data propuesta por Hadley Wickham (Wickham et al. 2014) y pueden instalarse con una única orden en R:
install.packages("tidyverse")Una vez instalado, se cargan con la función library:
library(tidyverse)Los paquétes más importantes en ciencia de datos se enumeran a continuación.
![]()
2.2.1 readr
El paquete readr roporciona una forma rápida y amigable de leer datos rectangulares (como csv, tsv y fwf). Está diseñado para analizar de forma flexible muchos tipos de datos que se encuentran en la naturaleza, mientras que sigue fallando limpiamente cuando los datos cambian inesperadamente.
readr admite los siguientes formatos de archivo asociados a estas funciones read_*():
read_csv(): valores separados por coma, ficheros (CSV).read_tsv(): valores separados por tabulador, fichero (TSV).read_delim(): fichro delimitados (CSV y TSV son casos especiales).read_fwf(): archivos de ancho fijo.read_table(): archivos separados por espacios en blancoread_log(): archivos de logos web.
Lea la base de datos de calidad del aire de la ciudad de Madrid , air_mad.RDS, contenida en la carpeta data.
(TODO): QUITAR LA FUNCIÓN HERE PORQUE A ESTE NIVEL SI NO SE EXPLICA PUEDE LIAR
air_mad <- readr::read_rds("data/air_mad.RDS")![]()
2.2.2 dplyr
El paquete dplyr Ofrece una gramática de la manipulación de datos, proporcionando un conjunto coherente de verbos que resuelven los problemas más comunes de manipulación de datos y que pueden ser organizado tres categorías basado en el dataset:
- Filas:
filter(): elige filas en función de los valores de la columna.slice(): elige filas en función de la ubicación.arrange(): cambia el orden de las filas.
- Columnas:
select(): indica cuando una columa es incluida o no.rename(): cambia el nombre de la columna.mutate(): cambia los valores de las columnas y crea nuevas columnas.relocate(): cambia el orden de las columnas.
- Grupos de filas:
summarise(): contrae un grupo en una sola fila.
El operador pipe
Canaliza la salida de una función a la entrada de otra función.
segundo(primero(datos))se traduce en:
datos %>%
primero %>%
segundoOperador pipe de {maggrit} %>% Operador pipe de R base |>
Ejemplo. Medidas de posición por estación de monitoreo
Calcule las medidas de posición (mínimo, máximo, Q1, Q3, media y mediana) por estación de monitoreo , agrupando por id_name para Partículas < 2.5 µm nom_abv == "PM2.5" utilizando las funciones de la libreria dplyr.
air_mad %>% # Summary por grupo usando dplyr
na.omit() %>% # omitimos los NAs para el análisis
filter(V == "V" & nom_abv == "PM2.5") %>% # filtramos por PM2.5
group_by(id_name) %>%
summarize(min = min(valor),
q1 = quantile(valor, 0.25),
median = median(valor),
mean = mean(valor),
q3 = quantile(valor, 0.75),
max = max(valor))# A tibble: 8 × 7
id_name min q1 median mean q3 max
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Casa de Campo 1 5 8 9.05 12 83
2 Castellana 1 6 9 9.65 12 62
3 Cuatro Caminos 1 6 9 10.1 13 59
4 Escuelas Aguirre 2 7 10 10.9 14 84
5 Méndez Álvaro 1 6 9 10.3 13 78
6 Plaza Castilla 1 6 9 9.53 12 76
7 Plaza Elíptica 1 7 10 10.9 14 61
8 Sanchinarro 1 5 7 8.44 10 68![]()
2.2.3 tidyr
El paquete tidyr proporciona un conjunto de funciones que le ayudan a obtener datos ordenados. Los datos ordenados son datos con una forma consistente. En resumen, cada variable va en una columna, y cada columna es una variable.
Las funciones se agrupan en 5 grandes categorías:
Pivotar. Convierte entre formas largas y anchas,
pivot_longer()ypivot_wider()Rectangling. Convierte listas profundamente anidadas (a partir de JSON) en
tibblesordenados:unnest_longer(),unnest_wider(),hoist().Anidar. Convierte los datos agrupados en una forma en el que cada grupo se convierte en una sola fila que contiene un data frame anidado
nest()y viceversa,unnest().Dividir y combinar columnas de caracteres. Funciones:
separate(),extract()yunite()Valores perdidos. Funciones:
complete(),drop_na(),fill(),replace_na()
Ejemplo. ¿Cuál es el día con mayor y menor concentración de NOx de todo el periodo?
air_mad %>% # Summary por grupo usando dplyr
na.omit() %>% # omitimos los NAs para el análisis
filter(V == "V" & nom_abv == "NOx") %>% # filtramos por NOx
group_by(fecha) %>% # agrupamos por fecha
summarize(mad_mean = mean(valor)) %>% # promedio de las estaciones
slice(which.max(mad_mean), which.min(mad_mean)) #seleccionamos el máximo y el mínimo # A tibble: 2 × 2
fecha mad_mean
<date> <dbl>
1 2014-12-18 390.
2 2020-05-10 6.38El valor máximo, 415 µg/m3 de NOx, se observa el 21 de diciembre de 2011 y el valor mínimo, 6,32 µg/m3 de NOx, el 10 de mayo de 2020, en pleno estado de alarma.
![]()
2.2.4 ggplot2
El paquete ggplot2 es un sistema para crear gráficos de forma ordenada, basado en The Grammar of Graphics. Al proporcionar los datos, le dice a ggplot2 cómo asignar a las variables la estética y qué gráficas utilizar.
El template básico para la función ggplot() es:
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(mapping = aes(<MAPPINGS>))Los argumentos más importantes para la representación de gráficos son:
ggplot(), crea un nuevo gráfico.aes(), construye la estética el gráfico.+(<gg>), añade componentes al gráfico.ggsave(), guarda el gráfico.
Ejemplo. Gráfico de violín.
Represente, con un gráfico de violín, las concentraciones de NOx por año en el periodo estudiado.
Una buena forma de ver los datos es por medio de un gráfico de violín:
air_mad %>% # Summary por grupo usando dplyr
na.omit() %>% # omitimos los NAs para el análisis
filter(V == "V" & nom_abv == "NOx") %>% # filtramos por NOx
group_by(year = format(fecha, "%Y")) %>%
summarise(valor) %>%
ggplot(aes(factor(year), valor))+
geom_violin() +
geom_jitter(height = 0, width = 0.01) +
aes(x=factor(year), y=valor, fill=year)
Note
Libro de referencia obligatoria: ggplot2: elegant graphics for data analysis.
Es interesante conocer las Extensiones de ggplot2 así como las ggplot2 Cheat sheet disponible.
![]()
2.2.5 purrr
El paquete purrr mejora el conjunto de herramientas de programación funcional (PF) de R proporcionando un conjunto completo y coherente de herramientas para trabajar con funciones y vectores. Una vez que se dominan los conceptos básicos, purrr permite sustituir muchos bucles for por un código más fácil de escribir y más expresivo.
Note
Consulte la purrr Cheat sheet disponible para una descripcion de la librería.
![]()
2.2.6 tibble
El paquete tibble es una reimaginación moderna del marco de datos, manteniendo lo que el tiempo ha demostrado que es eficaz, y desechando lo que no. Los Tibbles suelen conducir a un código más limpio y expresivo.
Tip
Consulte el capítulo 10 de R for data science disponible online para una primera aproximación.
![]()
2.2.7 stringr
El paquete stringr proporciona un conjunto cohesivo de funciones diseñadas para facilitar al máximo el trabajo con cadenas.
Tip
Consulte el capítulo 14 de R for data science disponible online para una primera aproximación.
![]()
2.2.8 forcats
El paquete forcats proporciona un conjunto de herramientas útiles que resuelven problemas comunes con los factores. R utiliza factores para manejar variables categóricas, variables que tienen un conjunto fijo y conocido de valores posibles.
Note
Consulte el capítulo 14 de R for data science disponible online para una primera aproximación.
2.3 Informes reproducibles con Quarto/Rmarkdown
Este es un documento R Quarto. Quarto es una sintaxis simple de formato para la creación de documentos HTML, PDF y MS Word. Para obtener más detalles sobre cómo usar R Quarto consulta https://quarto.org/.
RMarkdown (el antecesor de Quarto) y Quarto son herramientas permiten combinar texto formateado con código y resultados en un mismo documento. Quarto facilita la interoperabilidad entre R, Python, Julia.
Los documentos Quarto constan principalmetne de 3 partes: + el YAML (o cabecera del documento),
el texto (cuerpo escrito del documento),
las chunks (tozos de código, en este caso, código R)
A continuación se exponen, brevemente, las principales ideas para entender y trabajar sintaxis quarto.
2.3.1 Introducción
2.3.1.1 Markdown: un lenguaje de marcado ligero
Markdown es un lenguaje de marcado ligero y fácil de aprender que permite dar formato al texto de manera sencilla. Con Markdown, es posible aplicar negrita, cursiva, encabezados, listas y enlaces, entre otras opciones de formato, simplemente utilizando una sintaxis intuitiva. La facilidad de uso del lenguaje Markdown hace que sea ampliamente utilizado, sobre todo para la documentación.
2.3.1.2 Integración de código y resultados
Una de las características principales de Quarto/Rmarkdown es la capacidad de integrar código en el informe. Esto significa que se pueden incluir bloques de código o chunks en lenguajes como R, Python o Julia directamente en el documento. Estos bloques de código se ejecutan en tiempo real y los resultados, como tablas o gráficos, se incrustan automáticamente en el informe. Esto permite a los lectores ver tanto el código como los resultados generados, lo que promueve la transparencia y la reproducibilidad.
2.3.1.3 Generación de múltiples formatos de salida
Quarto ofrece la posibilidad de generar informes en diferentes formatos de salida, como por ejemplo: HTML, PDF, Word o presentaciones de diapositivas. Esto es especialmente útil cuando se necesita compartir el informe con diferentes audiencias o cuando se requiere una presentación visualmente atractiva. La conversión entre formatos se realiza de manera automática y se puede personalizar para que se adapte a las necesidades específicas de cada proyecto.
2.3.1.4 Facilidad de uso y colaboración
Quarto se integra con RStudio, lo que proporciona una experiencia de usuario fluida y amigable. Además, los archivos Rmarkdown son archivos de texto plano, lo que hace que sean fáciles para el control de versiones como Git. Esto facilita el trabajo en equipo y la colaboración en proyectos.
2.3.2 Instalación
Para poder utilizar Quarto/Rmarkdown en R y RStudio, es necesario realizar algunos pasos de instalación. A continuación, se detallan los pasos necesarios:
- Instalar R (véase (instal-r-rstudio?)).
- Instalar RStudio (véase (instal-r-rstudio?)).
- Intalar Quarto: para ello hay que dirigirse a la página oficial de Quarto, acceder al apartado Get Started y seleccionar la instalación acorde al sistema operativo. POsteriormente hay que seguir los pasos del instalador.
- Instalar el paquete Quarto: Una vez que R, RStudio y Quarto, se debe instalar la librería de Quarto para habilitar la funcionalidad de Quarto en R y RStudio. Para ello, se puede ejecutar el siguiente comando en la consola de RStudio:
install.packages("quarto")
Después de la instalación, se debe configurar RStudio para utilizar Quarto como el motor de renderizado de Rmarkdown. Para ello, se debe abrir la pestaña Tools (Herramientas) en la barra de menú de RStudio y seleccionar Global Options (Opciones globales). En la ventana emergente, selecciona la pestaña R Markdown y asegúrate de que la opción Quarto esté seleccionada en la sección Render.
Con estos pasos completados, ya se puede comenzar a utilizar Quarto en RStudio para crear informes reproducibles. Se puede crear un nuevo archivo Rmarkdown y comenzar a combinar texto y código en un solo documento.
2.3.3 El YAML
La sintaxis básica de YAML utiliza pares clave-valor en el formato clave: valor. Otros campos YAML comúnmente encontrados en los encabezados de los documentos incluyen metadatos como author (autor), subtitle (subtítulo), date (fecha), así como opciones de personalización como theme (tema), fontcolor (color de la fuente), fig-width (ancho de la figura), etc. Se puede encontrar información sobre todos los campos YAML disponibles para documentos HTML en la página oficial de Quarto. Los campos YAML disponibles varían según el formato del documento, por ejemplo,los campos YAML para documentos PDF y para MS Word.
---
title: "My Document"
author:
- Gema Fernández-Avilés
- Michal Kinel
format:
html:
toc: true
code-fold: true
---
2.3.4 Flujo de trabajo y el concepto renderizar
Un informe en Quarto/Rmarkdown se compone de bloques de texto y bloques de código. El texto se escribe en formato Markdown. Los bloques de código, chunks se delimitan con etiquetas especiales y pueden contener código en R, Python u otros lenguajes compatibles.
Note
renderizar en RMarkdown/Quarto se refiere al proceso de transformar un documento escrito en lenguaje Markdown, que combina texto y código, en un formato final legible y presentable, como un informe, un documento PDF o una página web interactiva.
El proceso de renderizado se realiza mediante la ejecución de un motor de renderizado, como Quarto, que interpreta el documento RMarkdown y produce el resultado final en el formato deseado, como un archivo HTML, PDF, Word, entre otros. Durante el proceso de renderizado, el motor ejecuta el código R, genera los gráficos y tablas correspondientes, y aplica el formato y estilo definidos en el documento.
La mejor manera de tejer un html_document es mediante el botón Render o la función quarto::quarto_render().

2.3.4.1 Trozos de código chunks
Los bloques de código en Quarto/Rmarkdown se utilizan para incorporar código fuente en el informe. Estos bloques se delimitan mediante etiquetas especiales, como {r} para código en R o {python} para código en Python. Dentro de estos bloques, se puede escribir y ejecutar código de la misma manera que se haría en un entorno de programación normal.
La ejecución del código se realiza en tiempo real, lo que significa que los resultados generados, como tablas, gráficos o textos formateados, se incrustan directamente en el informe cuando se renderiza. Esto permite a los lectores ver los resultados obtenidos y verificar la reproducibilidad del análisis.
Se puede insertar rápidamente bloques de código con el comando Agregar Bloque en la barra de herramientas del editor o escribiendo los delimitadores de bloque:
2+2[1] 4La salida de una chunk se puede personalizar con las opciones de knitr. Algunas de las más usadas son:
|# include: falseevita que el código y los resultados aparezcan en el archivo final. R Markdown sigue ejecutando el código en el chunk, y los resultados pueden ser utilizados por otros chunks.|# echo : falseevita que el código, pero no los resultados, aparezcan en el archivo final. Es una forma útil de incrustar cifras.|# message : falseevita que los mensajes generados por el código aparezcan en el archivo final.|# warning : falseevita que las advertencias generadas por el código aparezcan en el acabado.|# fig.cap : "..."añade una leyenda a los resultados gráficos.
Más información sobre la opción de trozos de código: Quarto chunks.
2.3.4.2 Formato de texto
El texto en formato Markdown se utiliza para proporcionar explicaciones, descripciones y contexto en el documento Escribir texto en Markdown es sencillo, ya que no requiere conocimientos avanzados de programación. Con Markdown, se pueden aplicar diferentes estilos de formato utilizando una sintaxis sencilla y legible.
Se pueden añadir enlaces, escribir en negrita o cursiva. Consulta la hoja de trucos de Rstudio descargar aquí.
Hacer citas
bloque de línea
Otros formatos de texto:
- subrayado
tachar- superíndice
- subíndice
- versalitas
La forma de añadir notas a pie de página es [^number]2
También se puede añadir emojis increíbles como 😻 insertándolo en el editor visual markdown o mediante su código :heart_eyes_cat:.
A veces es necesario separar el texto con una línea horizontal, para ello simplemente se introduce ***
o saltar una línea con código html <br><br><br><br>.
2.3.4.3 Añadir una imagen
Para añadir imágenes basta con escribir 

Si desea centrar la imagen, un poco de código htm le ayudará, sólo tiene que utilizar <center> </center>

Para ajustar las imágenes puedes usar r chunk añadiendo la imagen con una función knitr::include_graphics
knitr::include_graphics("https://bookdown.org/oscar_teach/estadistica_aplicada_con_r/r-rstudio.png")
plot(cars)
plot(pressure)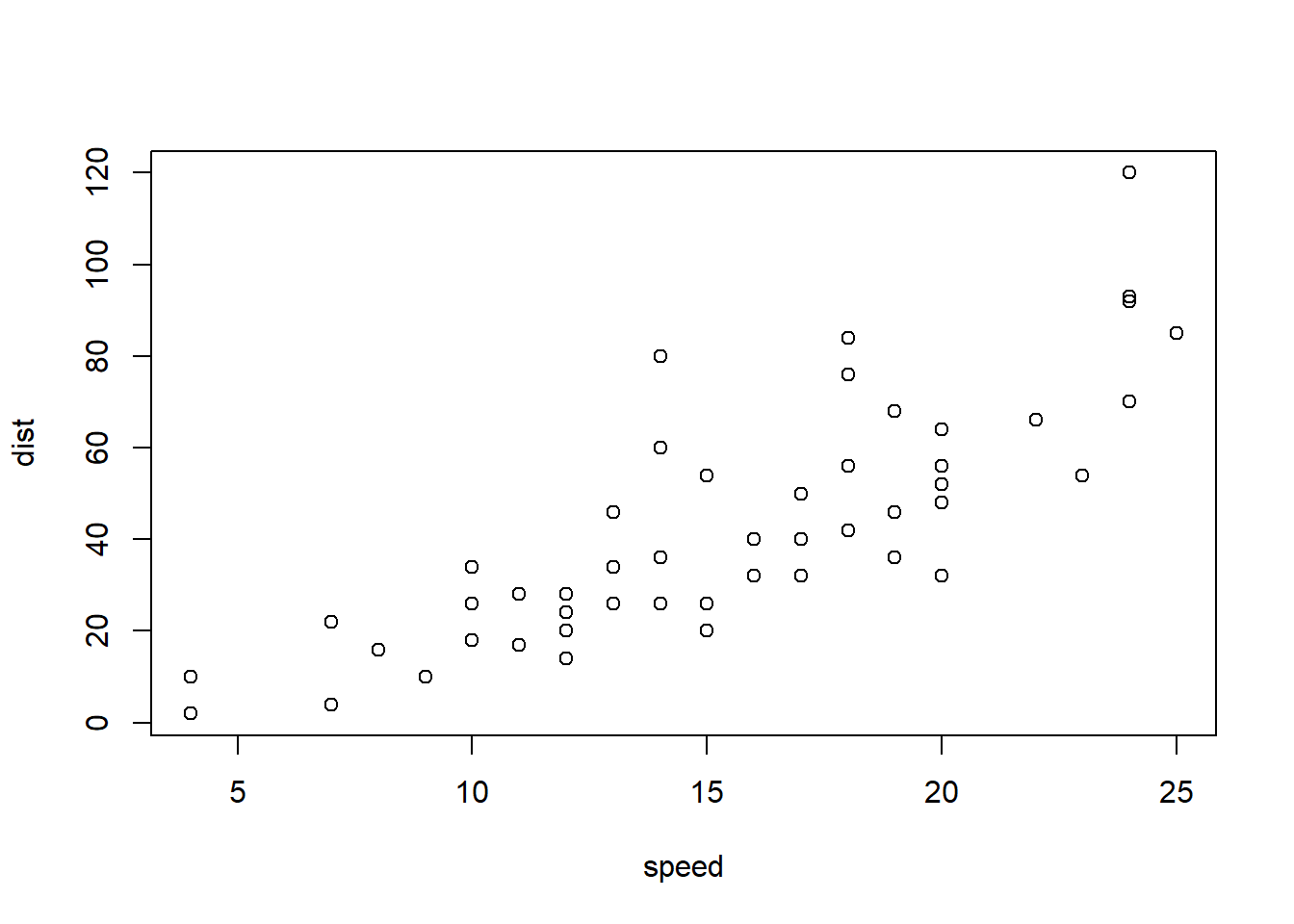
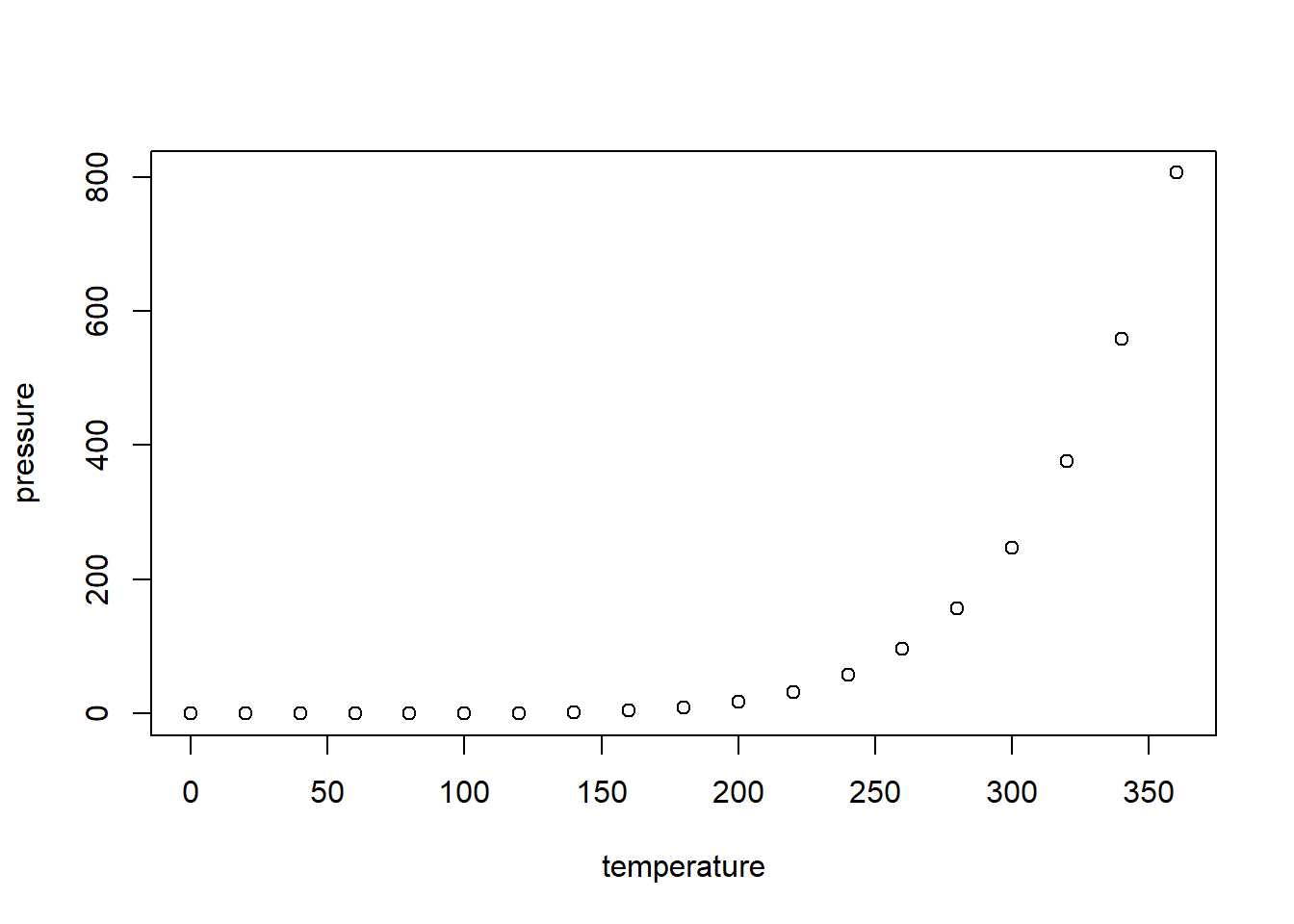
Véanse ejemplos en Figure 2.4. En particular, Figure 2.4 (b).
2.3.4.4 Ecuaciones
Insertar ecuaciones en un documento Quarteo es fácil utilizando la escritura Latex + en línea: \(A = (\pi * \lambda \times r^{4}) / \alpha\)
- centradas: \[A = (\pi * \lambda \times r^{4}) / \alpha\]
2.3.4.5 Diagramas
Quarto tiene soporte nativo para incrustar diagramas Mermaid y Graphviz. Esto te permite crear diagramas de flujo, diagramas de secuencia, diagramas de estado, diagramas gnatt, y más usando una sintaxis de texto plano inspirada en markdown.
Por ejemplo, aquí se incrusta un diagrama de flujo creado con Mermaid:
flowchart LR
A[Hard edge] --> B(Round edge)
B --> C{Decision}
C --> D[Result one]
C --> E[Result two]
Gantt diagram:
gantt dateFormat YYYY-MM-DD title Adding GANTT diagram to mermaid excludes weekdays 2014-01-10 section A section Completed task :done, des1, 2014-01-06,2014-01-08 Active task :active, des2, 2014-01-09, 3d Future task : des3, after des2, 5d Future task2 : des4, after des3, 5d
2.3.4.6 Bloques de llamada
Note
Tenga en cuenta que hay cinco tipos de llamadas, incluyendo: note, tip, warning, caution, and important.
2.3.4.7 Listas
- ítem X
- ítem Y
- ítem Z
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur gravida eu erat et fring. Morbi congue augue vel eros ullamcorper, eget convallis tortor sagittis. Fusce sodales viverra mauris a fringilla. Donec feugiat, justo eu blandit placerat, enim dui volutpat turpis, eu dictum lectus urna eu urna. Mauris sed massa ornare, interdum ipsum a, semper massa.
2.3.4.8 Apéndice
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
2.3.4.9 Citaciones
R Markdown The Definitive Guide (Xie, Allaire, and Grolemund 2018)
2.3.5 Renderizado
Utiliza el botón de Render en el entorno de desarrollo integrado (IDE) de RStudio para renderizar el archivo y previsualizar el resultado con un solo clic o combinación de teclas (⇧⌘K).
knitr::include_graphics("img/rstudio-render.png")
Si se prefiere renderizar automáticamente cada vez que se guarda el documento, se puede activar la opción de Renderizar al Guardar (Render on Save) en la barra de herramientas del editor. La previsualización se actualizará cada vez que vuelvas a renderizar el documento. La vista de previsualización en paralelo funciona tanto para salidas en HTML como en PDF.
2.4 Buscar ayuda en R o sobre R (funciones, paquetes, errores)
Las funciones de distintos paquetes de R tienen su ayuda y es muy fácil acceder a ella desde la consola poniendo un signo de interrogación delante de la función, por ejemplo al ejecutar ?mean en la consola se abrirá la ventana de Help con la descripción de la función, su uso, los argumentos y otros datos relevantes que nos permitirán entender mejor la función que ejecutamos. También, existe una amplia información online sobre las funciones y distintos paquetes disponible en Rdocumentation.org.
2.4.1 Haz preguntas
Uno de los foros más amplio de búsqueda de preguntas y respuestas sobre la programación es StackOverflow. En StackOverflow se registraron hasta el momento más 450.000 preguntas. Se puede navegar por los archivos de StackOverflow y ver qué respuestas han sido votadas por los usuarios, o puedes hacer tus propias preguntas relacionadas con R y esperar una respuesta.
2.4.2 Sigue la comunidad de R
Existen diversas páginas web que contienen artículos sobre la programación en R, como por ejemplo:
R bloggers: un agregador de blogs que vuelve a publicar artículos relacionados con R de toda la web. Un buen lugar para encontrar tutoriales de R,
RWeekly: R Weekly se fundó el 20 de mayo de 2016. R está creciendo muy rápidamente, y hay un montón de grandes blogs, tutoriales y otros formatos de recursos que salen cada día. R Weekly quiere hacer un seguimiento de estas grandes cosas en la comunidad de R y hacerla más accesible para todos.
RPubs: RStudio permite aprovechar el poder de R Markdown para crear documentos que entrelazan su escritura y la salida de su código R. En RPubs se puede publicar esos documentos en la web en un click.
Medium: un sitio web de blogs donde se puede encontrar mucha temática sobre el Data Science.
2.5 Git y GitHub
¿Git y GitHub? En primer lugar, son dos cosas distintas:
Git es un software de código abierto para el control de versiones. Con Git puedes hacer cosas como ver todas las versiones anteriores del código que has creado en un proyecto.
GitHub es el servicio más popular (otros son GitLab y BitBucket) para colaborar en el código utilizando Git.
2.5.1 ¿Por qué debería usar Git y GitHub?
Las tres principales ventajas de utilizar Git y GitHub son:
El uso de Git y GitHub sirve como copia de seguridad. Dado que GitHub tiene una copia de todo el código que tienes localmente, si algo le ocurriera a tu ordenador, seguirías teniendo acceso a tu código.
El uso de Git y GitHub te permite utilizar el control de versiones. ¿Alguna vez has tenido documentos llamados trabajo_final.pdf, trabajo_final_2.pdf o este_es_el_final.pdf? En lugar de hacer copias de los archivos por miedo a perder el trabajo, el control de versiones permite ver lo que se hizo en el pasado, todo ello manteniendo versiones únicas de los documentos.
El uso de Git y GitHub hace posible trabajar en el mismo proyecto al mismo tiempo con distintos colaboradores. Se puede ver el autor de los cambios y se fuera necesario volver a la versión anterior.
Para poner Git y GitHub a punto lo mejor es seguir la guía de Happy Git and GitHub for the useR en la que se explica paso a paso como registrarse en GitHub e instalar Git, además de integrarlo en RStuidio.
Wickham, Hadley, and Garrett Grolemund. 2016. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. " O’Reilly Media, Inc.".
Xie, Yihui, Joseph J Allaire, and Garrett Grolemund. 2018. R Markdown: The Definitive Guide. CRC Press.
La “Comprehensive R Archive Network” (CRAN) es una colección de sitios que contienen material idéntico, consistente en la(s) distribución(es) de R, las extensiones aportadas, la documentación para R y los binarios. El sitio principal de CRAN en la WU (Wirtschaftsuniversität Wien) en Austria puede encontrarse en la URL https://CRAN.R-project.org/ y se refleja diariamente en muchos sitios de todo el mundo.↩︎
la nota a pie de página↩︎